一. 前言
Anscombe's quartet, 安斯库姆四重奏.
make thing better and simpler.
Anscombe's quartet, 安斯库姆四重奏.
注意不是vlookup, 是lookup.
碰到一个这样的问题, 下面动图的函数实现原理:

(图源: LOOKUP函数10种经典用法 新手必看)
这个函数并不难理解, 比较大的坑点, 在于其查询内容是需要经过排序的.
注意这里的排序, 这个点类似于pandas中的loc在定位不到数据时(这个功能在pandas上正逐步被废弃), 假如数据不是经过排序, 其返回的内容是异常的.
相关内容见, NoteBook/Pandas-loc的执行逻辑.ipynb at main - Kyouichirou/NoteBook (github.com)
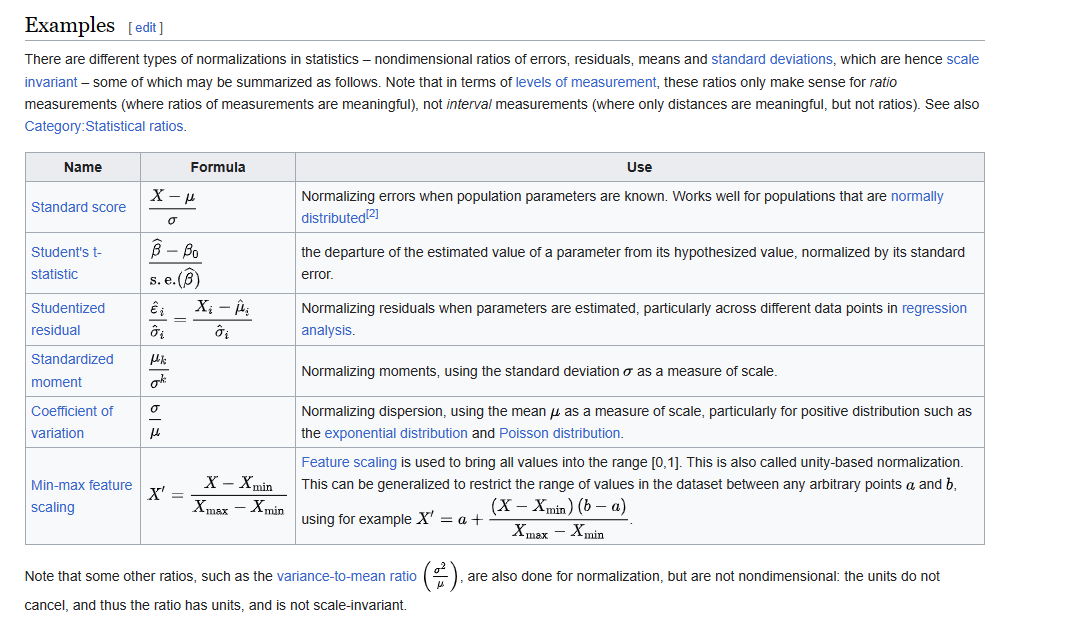
In statistics and applications of statistics, normalization can have a range of meanings.[1] In the simplest cases, normalization of ratings means adjusting values measured on different scales to a notionally common scale, often prior to averaging. In more complicated cases, normalization may refer to more sophisticated adjustments where the intention is to bring the entire probability distributions of adjusted values into alignment. In the case of normalization of scores in educational assessment, there may be an intention to align distributions to a normal distribution. A different approach to normalization of probability distributions is quantile normalization, where the quantiles of the different measures are brought into alignment.
在Wikipedia中, 以下的操作都归于Normalization(统计学的概念上).
突然被问, excel如何实现中国式排名?
| 值 | 排名 |
|---|---|
| 1 | 1 |
| 1 | 1 |
| 2 | 2, 还是延续上面的序号, 而不是直接跳到3, 这种方式就称为中国式排名 |
| 3 | 3 |
| 4 | 4 |
即, 在排的值中出现重复值时该如何处理接下来的序号.
在MySQL的窗口函数, 针对排名的问题提供了三种模式:

(图: 知乎-相关问题)(题目写错了?, mmape?)
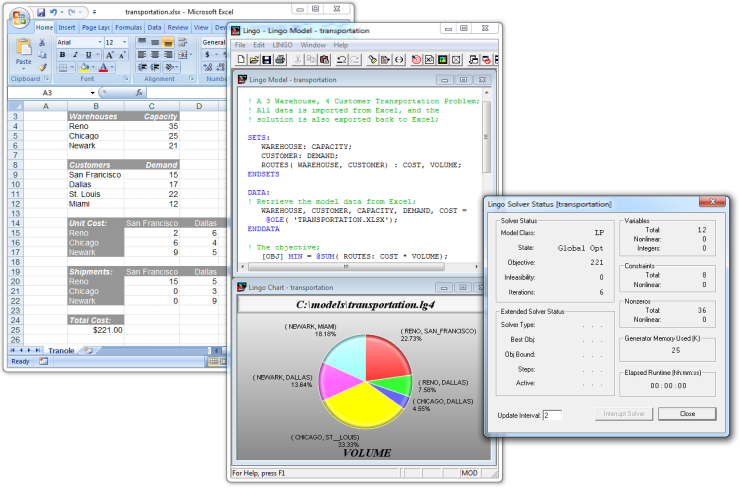
LINGO is a comprehensive tool designed to make building and solving Linear, Nonlinear (convex & nonconvex/Global), Quadratic, Quadratically Constrained, Second Order Cone, Semi-Definite, Stochastic, and Integer optimization models faster, easier and more efficient. LINGO provides a completely integrated package that includes a powerful language for expressing optimization models, a full featured environment for building and editing problems, and a set of fast built-in solvers.
在当下各种近乎于浮夸的("大")数据处理工具面前, lingo可谓是一个另类的存在, 其官网上也没有各种高大上的宣传概念(动辄大数据, 神经网络..机器学习...), 是个相当相当低调的数学处理工具, 甚至其操作界面至今还维持上古时代vb的极简风格.
(但是, 需要注意, 这并不意味着这个软件的开发的停止..这个软件还持续更新, 当下版本20)
在机器学习-梯度下降一文主要介绍了梯度下降在一元线性回归拟合的内容, 这里进一步延申讨论一元线性回归各种细节问题.

(图: 豆瓣读书-复分析导论)
在检索算法, 模型, 高阶数学等内容时常遇到的问题, 各种模棱两可, 似是而非的信息. 多查多看.
本文主要讨论的是底层数学处理相关的问题, 如方程, 矩阵, 积分等实际的计算.
更多使用示例见其他文章, 如, 报童问题详解, 各种库在实际中的是如何使用的, 都起到些什么作用.
知微见著
更多内容见: https://nbviewer.org/github/Kyouichirou/NoteBook/blob/main/Plotly/Plotly柱状图详解.ipynb
通过对柱状图(bar)解析plot的绘图机制和各种参数使用, 以便于理解其整体的作业逻辑.
和pandas的read_csv类似, 大部分的参数, 执行逻辑在其他对象上也是类似的.
